Exam Code: DOP-C01 (Practice Exam Latest Test Questions VCE PDF)
Exam Name: AWS Certified DevOps Engineer- Professional
Certification Provider: Amazon-Web-Services
Free Today! Guaranteed Training- Pass DOP-C01 Exam.
Online Amazon-Web-Services DOP-C01 free dumps demo Below:
NEW QUESTION 1
You've been tasked with improving the current deployment process by making it easier to deploy and reducing the time it takes. You have been tasked with creating a continuous integration (CI) pipeline that can build AMI'S. Which of the below is the best manner to get this done. Assume that at max your development team will be deploying builds 5 times a week.
- A. Use a dedicated EC2 instance with an EBS Volum
- B. Download and configure the code and then crate an AMI out of that.
- C. Use OpsWorks to launch an EBS-backed instance, then use a recipe to bootstrap the instance, and then have the CI system use the Createlmage API call to make an AMI from it.
- D. Upload the code and dependencies to Amazon S3, launch an instance, download the package fromAmazon S3, then create the AMI with the CreateSnapshot API call
- E. Have the CI system launch a new instance, then bootstrap the code and dependencies on that instance, and create an AMI using the Createlmage API call.
Answer: D
Explanation:
Since the number of calls is just a few times a week, there are many open source systems such as Jenkins which can be used as CI based systems.
Jenkins can be used as an extensible automation server, Jenkins can be used as a simple CI server or turned into the continuous delivery hub for any project.
For more information on the Jenkins CI tool please refer to the below link:
• https://jenkins.io/
Option A and C are partially correct, but since you just have 5 deployments per week, having separate instances which consume costs is not required. Option B is partially correct, but again having a separate system such as Opswork for such a low number of deployments is not required.
NEW QUESTION 2
The company you work for has a huge amount of infrastructure built on AWS. However there has been some concerns recently about the security of this infrastructure, and an external auditor has been given the task of running a thorough check of all of your company's AWS assets. The auditor will be in the USA while your company's infrastructure resides in the Asia Pacific (Sydney) region on AWS. Initially, he needs to check all of your VPC assets, specifically, security groups and NACLs You have been assigned the task of providing the auditor with a login to be able to do this. Which of the following would be the best and most secure solution to provide the auditor with so he can begin his initial investigations? Choose the correct answer from the options below
- A. Createan 1AM usertied to an administrator rol
- B. Also provide an additional level ofsecurity with MFA.
- C. Givehim root access to your AWS Infrastructure, because he is an auditor he willneed access to every service.
- D. Createan 1AM user who will have read-only access to your AWS VPC infrastructure andprovide the auditor with those credentials.
- E. Createan 1AM user with full VPC access but set a condition that will not allow him tomodify anything if the request is from any IP other than his own.
Answer: C
Explanation:
Generally you should refrain from giving high level permissions and give only the required permissions. In this case option C fits well by just providing the relevant access which is required.
For more information on 1AM please see the below link:
• https://aws.amazon.com/iam/
NEW QUESTION 3
You are planning on configuring logs for your Elastic Load balancer. At what intervals does the logs get produced by the Elastic Load balancer service. Choose 2 answers from the options given below
- A. 5minutes
- B. 60minutes
- C. 1 minute
- D. 30seconds
Answer: AB
Explanation:
The AWS Documentation mentions
Clastic Load Balancing publishes a log file for each load balancer node at the interval you specify. You can specify a publishing interval of either 5 minutes or 60 minutes when you enable the access log for your load balancer. By default. Elastic Load Balancing publishes logs at a 60-minute interval.
For more information on Elastic load balancer logs please see the below link: http://docs.aws.amazon.com/elasticloadbalancing/latest/classic/access-log-collection.html
NEW QUESTION 4
You need to deploy a multi-container Docker environment on to Elastic beanstalk. Which of the following files can be used to deploy a set of Docker containers to Elastic beanstalk
- A. Dockerfile
- B. DockerMultifile
- C. Dockerrun.aws.json
- D. Dockerrun
Answer: C
Explanation:
The AWS Documentation specifies
A Dockerrun.aws.json file is an Clastic Beanstalk-specific JSON file that describes how to deploy a set of Docker containers as an Clastic Beanstalk application. You can use aDockerrun.aws.json file for a multicontainer Docker environment.
Dockerrun.aws.json describes the containers to deploy to each container instance in the environment as well as the data volumes to create on the host instance for the containers to mount.
For more information on this, please visit the below URL:
http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/create_deploy_docker_v2config.html
NEW QUESTION 5
Of the 6 available sections on a Cloud Formation template (Template Description Declaration, Template Format Version Declaration, Parameters, Resources, Mappings, Outputs), which is the only one required for a CloudFormation template to be accepted? Choose an answer from the options below
- A. Parameters
- B. Template Declaration
- C. Mappings
- D. Resources
Answer: D
Explanation:
If you refer to the documentation, you will see that Resources is the only mandatory field
Specifies the stack resources and their properties, such as an Amazon Elastic Compute Cloud instance or an Amazon Simple Storage Service bucket.
For more information on cloudformation templates, please refer to the below link:
• http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/template-anatomy.html
NEW QUESTION 6
You are in charge of designing a Cloudformation template which deploys a LAMP stack. After deploying a stack, you see that the status of the stack is showing as CREATE_COMPLETE, but the apache server is still not up and running and is experiencing issues while starting up. You want to ensure that the stack creation only shows the status of CREATE_COMPLETE after all resources defined in the stack are up and running. How can you achieve this?
Choose 2 answers from the options given below.
- A. Definea stack policy which defines that all underlying resources should be up andrunning before showing a status of CREATE_COMPLETE.
- B. Uselifecycle hooks to mark the completion of the creation and configuration of theunderlying resource.
- C. Usethe CreationPolicy to ensure it is associated with the EC2 Instance resource.
- D. Usethe CFN helper scripts to signal once the resource configuration is complete.
Answer: CD
Explanation:
The AWS Documentation mentions
When you provision an Amazon EC2 instance in an AWS Cloud Formation stack, you might specify additional actions to configure the instance, such as install software packages or bootstrap applications. Normally, CloudFormation proceeds with stack creation after the instance has been successfully created. However, you can use a Creation Pol icy so that CloudFormation proceeds with stack creation only after your configuration actions are done. That way you'll know your applications are ready to go after stack creation succeeds.
For more information on the Creation Policy, please visit the below url https://aws.amazon.com/blogs/devops/use-a-creationpolicy-to-wait-for-on-instance-configurations/
NEW QUESTION 7
You have a web application running on six Amazon EC2 instances, consuming about 45% of resources on each instance. You are using auto-scaling to make sure that six instances are running at all times. The number of requests this application processes is consistent and does not experience spikes. The application is critical to your business and you want high availability at all times. You want the load to be distributed evenly between all instances. You also want to use the same Amazon Machine Image (AMI) for all instances. Which of the following architectural choices should you make?
- A. Deploy6 EC2 instances in one availability zone and use Amazon Elastic Load Balancer.
- B. Deploy3 EC2 instances in one region and 3 in another region and use Amazon ElasticLoad Balancer.
- C. Deploy3 EC2 instances in one availability zone and 3 in another availability zone anduse Amazon Elastic Load Balancer.
- D. Deploy2 EC2 instances in three regions and use Amazon Elastic Load Balancer.
Answer: C
Explanation:
Option A is automatically incorrect because remember that the question asks for high availability. For option A, if the A2 goes down then the entire application fails.
For Option B and D, the CLB is designed to only run in one region in aws and not across multiple regions. So these options are wrong.
The right option is C.
The below example shows an Elastic Loadbalancer connected to 2 EC2 instances connected via Auto Scaling. This is an example of an elastic and scalable web tier.
By scalable we mean that the Auto scaling process will increase or decrease the number of CC2 instances as required.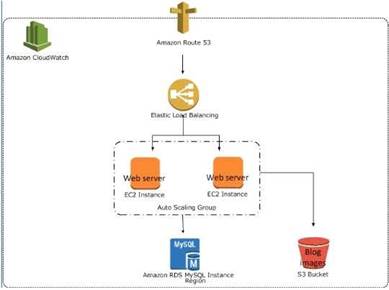
For more information on best practices for AWS Cloud applications, please visit the below URL:
• https://d03wsstatic.com/whitepapers/AWS_Cloud_Best_Practices.pdf
NEW QUESTION 8
Your application consists of 10% writes and 90% reads. You currently service all requests through a Route53 Alias Record directed towards an AWS ELB, which sits in front of an EC2 Auto Scaling Group. Your system isgetting very expensive when there are large traffic spikes during certain news events, during which many more people request to read similar data all at the same time. What is the simplest and cheapest way to reduce costs and scale with spikes like this?
- A. Create an S3 bucket and asynchronously replicate common requests responses into S3 object
- B. When a request comes in for a precomputed response, redirect to AWS S3.
- C. Create another ELB and Auto Scaling Group layer mounted on top of the other system, adding a tier to the syste
- D. Serve most read requests out of the top layer.
- E. Create a CloudFront Distribution and direct Route53 to the Distributio
- F. Use the ELB as an Origin and specify Cache Behaviours to proxy cache requests which can be served late.
- G. Create a Memcached cluster in AWS ElastiCach
- H. Create cache logic to serve requests which can be served late from the in-memory cache for increased performance.
Answer: C
Explanation:
Use Cloudf rant distribution for distributing the heavy reads for your application. You can create a
zone apex record to point to the Cloudfront distribution.
You can control how long your objects stay in a CloudFront cache before CloudFront forwards another request to your origin. Reducing the duration allows you to serve dynamic content. Increasing the duration means your users get better performance because your objects are more likely to be served directly from the edge cache. A longer duration also reduces the load on your origin.
For more information on Cloudfront object expiration, please visit the below URL: http://docs.aws.amazon.com/AmazonCloudFrant/latest/DeveloperGuide/Cxpiration.html
NEW QUESTION 9
Your company is planning to develop an application in which the front end is in .Net and the backend is in DynamoDB. There is an expectation of a high load on the application. How could you ensure the scalability of the application to reduce the load on the DynamoDB database? Choose an answer from the options below.
- A. Add more DynamoDB databases to handle the load.
- B. Increase write capacity of Dynamo DB to meet the peak loads
- C. Use SQS to assist and let the application pull messages and then perform the relevant operation in DynamoDB.
- D. Launch DynamoDB in Multi-AZ configuration with a global index to balance writes
Answer: C
Explanation:
When the idea comes for scalability then SQS is the best option. Normally DynamoDB is scalable, but since one is looking for a cost effective solution, the messaging in SQS can assist in managing the situation mentioned in the question.
Amazon Simple Queue Service (SQS) is a fully-managed message queuing service for reliably communicating among distributed software components and microservices - at any scale. Building applications from individual components that each perform a discrete function improves scalability and reliability, and is best practice design for modern applications. SQS makes it simple and cost- effective to decouple and coordinate the components of a cloud application. Using SQS, you can send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be always available
For more information on SQS, please refer to the below URL:
• https://aws.amazon.com/sqs/
NEW QUESTION 10
You have carried out a deployment using Elastic Beanstalk with All at once method, but the application is unavailable. What could be the reason for this
- A. You need to configure ELB along with Elastic Beanstalk
- B. You need to configure Route53 along with Elastic Beanstalk
- C. There will always be a few seconds of downtime before the application is available
- D. The cooldown period is not properly configured for Elastic Beanstalk
Answer: C
Explanation:
The AWS Documentation mentions
Because Elastic Beanstalk uses a drop-in upgrade process, there might be a few seconds of downtime. Use rolling deployments to minimize the effect of deployments on your production environments.
For more information on troubleshooting Elastic Beanstalk, please refer to the below link:
• http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/troubleshooting-deployments.html
• https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/using-features.de ploy-existing- version, html
NEW QUESTION 11
You are currently planning on using Autoscaling to launch instances which have an application installed. Which of the following methods will help ensure the instances are up and running in the shortest span of time to take in traffic from the users?
- A. Loginto each instance and install the software.
- B. UseUserData to launch scripts to install the software.
- C. UseDocker containers to launch the software.
- D. UseAMI's which already have the software installed.
Answer: D
Explanation:
The AM I will be the fatest because it will already have the software installed. You can customize the instance that you launch from a public AMI and then save that configuration as a custom AMI for your own use. Instances that you launch from your AMI use all the custom izations that you've made.
For more information on AMI'S please refer to the below link http://docs.aws.amazon.com/AWSCC2/latest/UserGuide/AMIs.html
NEW QUESTION 12
You use Amazon Cloud Watch as your primary monitoring system for your web application. After a
recent software deployment, your users are getting Intermittent 500 Internal Server Errors when using the web application. You want to create a Cloud Watch alarm, and notify an on-call engineer when these occur. How can you accomplish this using AWS services? Choose three answers from the options given below
- A. Deploy your web application as an AWS Elastic Beanstalk applicatio
- B. Use the default Elastic Beanstalk Cloudwatch metrics to capture 500 Internal Server Error
- C. Set a CloudWatch alarm on that metric.
- D. Install a CloudWatch Logs Agent on your servers to stream web application logs to CloudWatch.
- E. Use Amazon Simple Email Service to notify an on-call engineer when a CloudWatch alarm is triggered.
- F. Create a CloudWatch Logs group and define metric filters that capture 500 Internal Server Error
- G. Set a CloudWatch alarm on that metric.
- H. Use Amazon Simple Notification Service to notify an on-call engineer when a CloudWatch alarm is triggered.
Answer: BDE
Explanation:
You can use Cloud Watch Logs to monitor applications and systems using log data
Cloud Watch Logs uses your log data for monitoring; so, no code changes are required. For example, you can monitor application logs for specific literal terms (such as "NullReferenceCxception") or count the number of occurrences of a literal term at a particular position in log data (such as "404" status codes in an Apache access log). When the term you are searching for is found. Cloud Watch Logs reports the data to a CloudWatch metric that you specify. Log data is encrypted while in transit and while it is at rest
For more information on Cloudwatch logs please refer to the below link: http://docs^ws.amazon.com/AmazonCloudWatch/latest/logs/WhatlsCloudWatchLogs.html
Amazon CloudWatch uses Amazon SNS to send email. First, create and subscribe to an SNS topic.
When you create a CloudWatch alarm, you can add this SNS topic to send an email notification when the alarm changes state.
For more information on SNS and Cloudwatch logs please refer to the below link: http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/US_SetupSNS.html
NEW QUESTION 13
Management has reported an increase in the monthly bill from Amazon Web Services, and they are extremely concerned with this increased cost. Management has asked you to determine the exact cause of this increase. After reviewing the billing report, you notice an increase in the data transfer cost. How can you provide management with a better insight into data transfer use?
- A. Update your Amazon CloudWatch metrics to use five-second granularity, which will give better detailed metrics that can be combined with your billing data to pinpoint anomalies.
- B. Use Amazon CloudWatch Logs to run a map-reduce on your logs to determine high usage and data transfer.
- C. Deliver custom metrics to Amazon CloudWatch per application that breaks down application data transfer into multiple, more specific data points.D- Using Amazon CloudWatch metrics, pull your Elastic Load Balancing outbound data transfer metrics monthly, and include them with your billing report to show which application is causing higher bandwidth usage.
Answer: C
Explanation:
You can publish your own metrics to CloudWatch using the AWS CLI or an API. You can view statistical graphs of your published metrics with the AWS Management Console.
CloudWatch stores data about a metric as a series of data points. Each data point has an associated time stamp. You can even publish an aggregated set of data points called a statistic set.
If you have custom metrics specific to your application, you can give a breakdown to the management on the exact issue.
Option A won't be sufficient to provide better insights.
Option B is an overhead when you can make the application publish custom metrics Option D is invalid because just the ELB metrics will not give the entire picture
For more information on custom metrics, please refer to the below document link: from AWS http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.htmI
NEW QUESTION 14
You are creating an application which stores extremely sensitive financial information. All information in the system must be encrypted at rest and in transit. Which of these is a violation of this policy?
- A. ELB SSL termination.
- B. ELB Using Proxy Protocol v1.
- C. CloudFront Viewer Protocol Policy set to HTTPS redirection.
- D. Telling S3 to use AES256 on the server-side.
Answer: A
Explanation:
If you use SSL termination, your servers will always get non-secure connections and will never know whether users used a more secure channel or not. If you are using Elastic beanstalk to configure the ELB, you can use the below article to ensure end to end encryption. http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/configuring-https-endtoend.html
NEW QUESTION 15
By default in Opswork, how many application versions can you rollback up to?
- A. 1
- B. 2
- C. 3
- D. 4
Answer: D
Explanation:
The AWS Documentation mentions the following Restores the previously deployed app version. For example, if you have deployed the app three times and then run Rollback, the server will serve the app from the second deployment. If you run Rollback again, the server will serve the app from the first deployment. By default, AWS OpsWorks Stacks stores the five most recent deployments, which allows you to roll back up to four versions. If you exceed the number of stored versions, the command fails and leaves the oldest version in place.
For more information on Opswork app deployment, please visit the below U RL: http://docs.aws.amazon.com/opsworks/latest/userguide/workingapps-deploying.html
NEW QUESTION 16
You are a Devops Enginneer in your company. You have been instructed to ensure there is an automated backup solution in place for EBS Volumes. These snapshots need to be retained only for a period of 20 days. How can you achieve this requirement in an efficient manner?
- A. Usethe aws ec2 create-volume API to create a snapshot of the EBS Volum
- B. The usethe describe- volume to see those snapshots which are greater than 20 days andthen delete them accordingly using the delete-volume API call.
- C. UseLifecycle policies to push the EBS Volumes to Amazon Glacie
- D. Then use furtherlifecycle policies to delete the snapshots after 20 days.
- E. UseLifecycle policies to push the EBS Volumes to Amazon S3. Then use further lifecyclepolicies to delete the snapshots after 20 days.
- F. Use Amazon Data Lifecycle Manager to automate the process.
Answer: D
Explanation:
Use Amazon Data Lifecycle Manager (Amazon DLM) to automate the creation, retention, and deletion of snapshots taken to back up your Amazon EBS volumes.
Automating snapshot management helps you to:
•Protect valuable data by enforcing a regular backup schedule. Retain backups as required by auditors or internal compliance.
•Reduce storage costs by deleting outdated backups.
For more Information, Please check the below AWS Docs:
• https://docs.aws.amazon.com/AWSCC2/latest/UserGuide/snapshot-lifecycle.html
NEW QUESTION 17
After reviewing the last quarter's monthly bills, management has noticed an increase in the overall bill from Amazon. After researching this increase in cost, you discovered that one of your new services is doing a lot of GET Bucket API calls to Amazon S3 to build a metadata cache of all objects in the applications bucket. Your boss has asked you to come up with a new cost-effective way to help reduce the amount of these new GET Bucket API calls. What process should you use to help mitigate the cost?
- A. Update your Amazon S3 buckets' lifecycle policies to automatically push a list of objects to a new bucket, and use this list to view objects associated with the application's bucket.
- B. Create a new DynamoDB tabl
- C. Use the new DynamoDB table to store all metadata about all objects uploaded to Amazon S3. Any time a new object is uploaded, update the application's internalAmazon S3 object metadata cache from DynamoDB.C Using Amazon SNS, create a notification on any new Amazon S3 objects that automatical ly updates a new DynamoDB table to store allmetadata about the new objec
- D. Subscribe the application to the Amazon SNS topic to update its internal Amazon S3 object metadata cache from the DynamoDB tabl
- E. ^/
- F. Upload all files to an ElastiCache file cache serve
- G. Update your application to now read all file metadata from the ElastiCache file cache server, and configure the ElastiCache policies to push all files to Amazon S3 for long-term storage.
Answer: C
Explanation:
Option A is an invalid option since Lifecycle policies are normally used for expiration of objects or archival of objects.
Option B is partially correct where you store the data in DynamoDB, but then the number of GET requests would still be high if the entire DynamoDB table had to be
traversed and each object compared and updated in S3.
Option D is invalid because uploading all files to Clastic Cache is not an ideal solution.
The best option is to have a notification which can then trigger an update to the application to update the DynamoDB table accordingly.
For more information on SNS triggers and DynamoDB please refer to the below link:
◆ https://aws.amazon.com/blogs/compute/619/
NEW QUESTION 18
You have an application hosted in AWS. This application was created using Cloudformation Templates and Autoscaling. Now your application has got a surge of users which is decreasing the performance of the application. As per your analysis, a change in the instance type to C3 would resolve the issue. Which of the below option can introduce this change while minimizing downtime for end users?
- A. Copy the old launch configuration, and create a new launch configuration with the C3 instance
- B. Update the Auto Scalinggroup with the new launch configuratio
- C. Auto Scaling will then update the instance type of all running instances.
- D. Update the launch configuration in the AWS CloudFormation template with the new C3 instance typ
- E. Add an UpdatePolicy attribute to the Auto Scaling group that specifies an AutoScalingRollingUpdat
- F. Run a stack update with the updated template.
- G. Update the existing launch configuration with the new C3 instance typ
- H. Add an UpdatePolicy attribute to your Auto Scalinggroup that specifies an AutoScaling RollingUpdate in order to avoid downtime.
- I. Update the AWS CloudFormation template that contains the launch configuration with the new C3 instance typ
- J. Run a stack update with the updated template, and Auto Scaling will then update the instances one at a time with the new instance type.
Answer: B
Explanation:
Ensure first that the cloudformation template is updated with the new instance type.
The AWS::AutoScaling::AutoScalingGroup resource supports an UpdatePoIicy attribute. This is used to define how an Auto Scalinggroup resource is updated when
an update to the Cloud Formation stack occurs. A common approach to updating an Auto Scaling group is to perform a rolling update, which is done by specifying
the AutoScalingRollingUpdate policy. This retains the same Auto Scaling group and replaces old instances with new ones, according to the parameters specified.
Option A is invalid because this will cause an interruption to the users.
Option C is partially correct, but it does not have all the steps as mentioned in option B.
Option D is partially correct, but we need the AutoScalingRollingUpdate attribute to ensure a rolling update is peformed.
For more information on AutoScaling Rolling updates please refer to the below link:
• https://aws.amazon.com/premiumsupport/knowledge-center/auto-scaling-group-rolling- updates/
NEW QUESTION 19
Which of the following services from AWS can be integrated with the Jenkins continuous integration tool.
- A. AmazonEC2
- B. AmazonECS
- C. AmazonElastic beanstalk
- D. Allof the above
Answer: D
Explanation:
The following AWS sen/ices can be integrated with Jenkins
For more information on Jenkins in AWS, please refer to the below link:
https://dOawsstatic.com/whitepapers/DevOps/Jenkins_on_AWS.pdf
NEW QUESTION 20
You're building a mobile application game. The application needs permissions for each user to communicate and store data in DynamoDB tables. What is the best method for granting each mobile device that installs your application to access DynamoDB tables for storage when required? Choose the correct answer from the options below
- A. During the install and game configuration process, have each user create an 1AM credential and assign the 1AM user to a group with proper permissions to communicate with DynamoDB.
- B. Create an 1AM group that only gives access to your application and to the DynamoDB table
- C. Then, when writing to DynamoDB, simply include the unique device ID to associate the data with that specific user.
- D. Create an 1AM role with the proper permission policy to communicate with the DynamoDB tabl
- E. Use web identity federation, which assumes the 1AM role using AssumeRoleWithWebldentity, when the user signs in, granting temporary security credentials using STS.
- F. Create an Active Directory server and an AD user for each mobile application use
- G. When the user signs in to the AD sign-on, allow the AD server to federate using SAML 2.0 to 1AM and assign a role to the AD user which is the assumed with AssumeRoleWithSAML
Answer: C
Explanation:
Answer - C
For access to any AWS service, the ideal approach for any application is to use Roles. This is the first preference.
For more information on 1AM policies please refer to the below link:
http://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html
Next for any web application, you need to use web identity federation. Hence option D is the right option. This along with the usage of roles is highly stressed in the aws documentation.
The AWS documentation mentions the following
When developing a web application it is recommend not to embed or distribute long-term AWS credentials with apps that a user downloads to a device, even in an encrypted store. Instead, build your app so that it requests temporary AWS security credentials dynamically when needed using web identity federation. The
supplied temporary credentials map to an AWS role that has only the permissions needed to perform the tasks required by the mobile app.
For more information on web identity federation please refer to the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers_oidc.html
NEW QUESTION 21
You are in charge of designing a number of Cloudformation templates for your organization. You need to ensure that no one can accidentally update the production based resources on the stack during a stack update. How can this be achieved in the most efficient way?
- A. Createtags for the resources and then create 1AM policies to protect the resources.
- B. Usea Stack based policy to protect the production based resources.
- C. UseS3 bucket policies to protect the resources.
- D. UseMFA to protect the resources
Answer: B
Explanation:
The AWS Documentation mentions
When you create a stack, all update actions are allowed on all resources. By default, anyone with stack update permissions can update all of the resources in the stack. During an update, some resources might require an interruption or be completely replaced, resulting in new physical IDs or completely new storage. You can prevent stack resources from being unintentionally updated or deleted during a stack update by using a stack policy. A stack policy is a JSON document that defines the update action1.-; that car1 be performed on designated resources.
For more information on protecting stack resources, please visit the below url http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/protect-stack-resources.html
NEW QUESTION 22
You are trying to debug the creation of Cloudformation stack resources. Which of the following can be used to help in the debugging process?
Choose 2 answers from the options below
- A. UseCloudtrail to debugall the API call's sent by the Cloudformation stack.
- B. Usethe AWS CloudFormation console to view the status of yourstack.
- C. Seethe logs in the/var/log directory for Linux instances
- D. UseAWSConfig to debug all the API call's sent by the Cloudformation stack.
Answer: BC
Explanation:
The AWS Documentation mentions
Use the AWS Cloud Formation console to view the status of your stack. In the console, you can view a list of stack events while your stack is being created, updated, or
deleted. From this list, find the failure event and then view the status reason for that event.
For Amazon CC2 issues, view the cloud-init and cfn logs. These logs are published on the Amazon CC2 instance in the /var/log/ directory. These logs capture processes and command outputs while AWS Cloud Formation is setting up your instance. For Windows, view the L~C2Configure service and cfn logs
in %ProgramFiles%\Amazon\CC2ConfigService and C:\cfn\log.
For more information on Cloudformation Troubleshooting, please visit the below URL: http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/troubleshooting.html
NEW QUESTION 23
......
Recommend!! Get the Full DOP-C01 dumps in VCE and PDF From Dumpscollection.com, Welcome to Download: https://www.dumpscollection.net/dumps/DOP-C01/ (New 116 Q&As Version)