Master the DP-500 Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI content and be ready for exam day success quickly with this Examcollection DP-500 exam guide. We guarantee it!We make it a reality and give you real DP-500 questions in our Microsoft DP-500 braindumps.Latest 100% VALID Microsoft DP-500 Exam Questions Dumps at below page. You can use our Microsoft DP-500 braindumps and pass your exam.
Check DP-500 free dumps before getting the full version:
NEW QUESTION 1
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.
You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend defining a data source and view for the Parquet files. You recommend updating the query to use the view.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 2
You have a Power Bl tenant that contains 10 workspaces.
You need to create dataflows in three of the workspaces. The solution must ensure that data engineers can access the resulting data by using Azure Data Factory.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point
- A. Associate the Power Bl tenant to an Azure Data Lake Storage account.
- B. Add the managed identity for Data Factory as a member of the workspaces.
- C. Create and save the dataflows to an Azure Data Lake Storage account.
- D. Create and save the dataflows to the internal storage of Power BL
Answer: AB
NEW QUESTION 3
You have a Power Bl workspace that contains one dataset and four reports that connect to the dataset. The dataset uses Import storage mode and contains the following data sources:
• A CSV file in an Azure Storage account
• An Azure Database for PostgreSQL database
You plan to use deployment pipelines to promote the content from development to test to production. There will be different data source locations for each stage. What should you include in the deployment pipeline to ensure that the appropriate data source locations are used during each stage?
- A. parameter rules
- B. selective deployment
- C. auto-binding across pipelines
- D. data source rules
Answer: B
NEW QUESTION 4
You have a Power Bl dataset that contains two tables named Table1 and Table2. The dataset is used by one report.
You need to prevent project managers from accessing the data in two columns in Table1 named Budget and Forecast.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.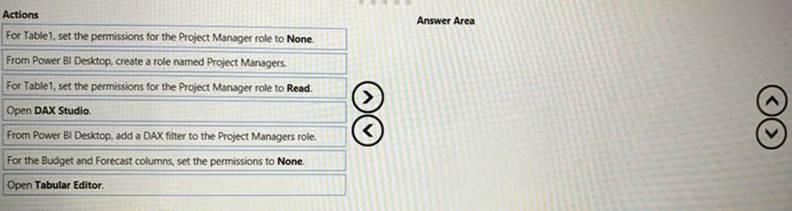
Solution:
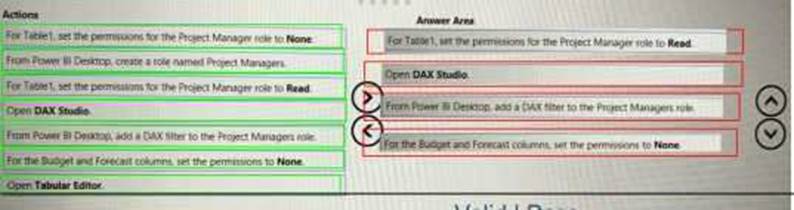
Does this meet the goal?
- A. Yes
- B. Not Mastered
Answer: A
NEW QUESTION 5
You have an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that the SQL pool is scanned by Azure Purview. What should you do first?
- A. Register a data source.
- B. Search the data catalog.
- C. Create a data share connection.
- D. Create a data policy.
Answer: B
NEW QUESTION 6
You open a Power Bl Desktop report that contains an imported data model and a single report page.
You open Performance analyzer, start recording, and refresh the visuals on the page. The recording produces the results shown in the following exhibit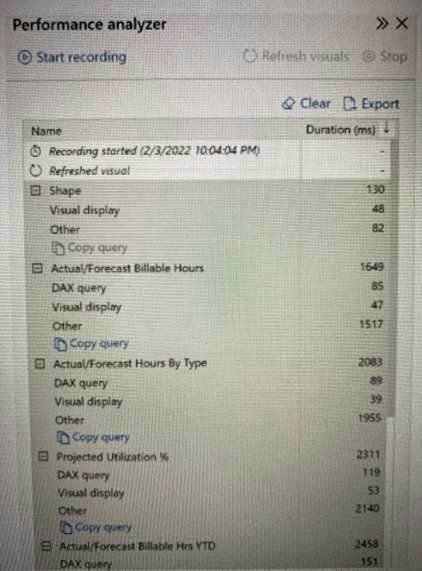
What can you identify from the results?
- A. The Actual/Forecast Hours by Type visual takes a long time to render on the report page when the data is cross-filtered.
- B. The Actual/Forecast Billable Hrs YTD visual displays the most data.
- C. Unoptimized DAX queries cause the page to load slowly.
- D. When all the visuals refresh simultaneously, the visuals spend most of the time waiting on other processes to finish.
Answer: D
NEW QUESTION 7
You develop a solution that uses a Power Bl Premium capacity. The capacity contains a dataset that is expected to consume 50 GB of memory.
Which two actions should you perform to ensure that you can publish the model successfully to the Power Bl service? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Increase the Max Offline Dataset Size setting.
- B. Invoke a refresh to load historical data based on the incremental refresh policy.
- C. Restart the capacity.
- D. Publish an initial dataset that is less than 10 GB.
- E. Publish the complete dataset.
Answer: CE
NEW QUESTION 8
You are configuring an aggregation table as shown in the following exhibit.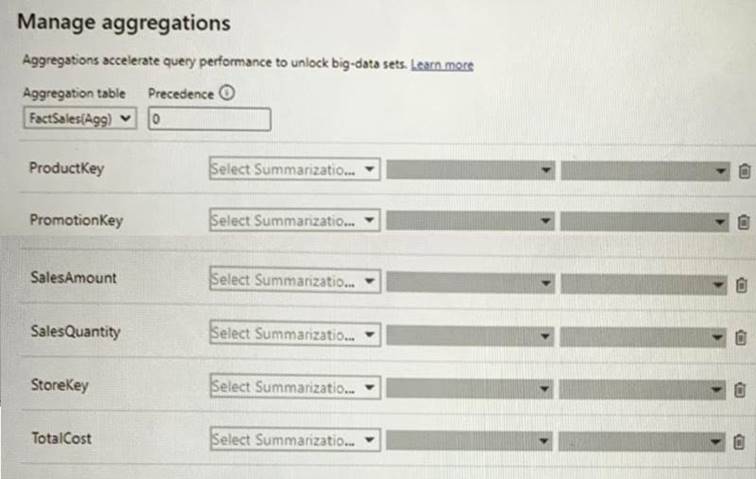
The detail table is named FactSales and the aggregation table is named FactSales(Agg). You need to aggregate SalesAmount for each store.
Which type of summarization should you use for SalesAmount and StoreKey? To answer, select the appropriate options in the answer area,
NOTE: Each correct selection is worth one point.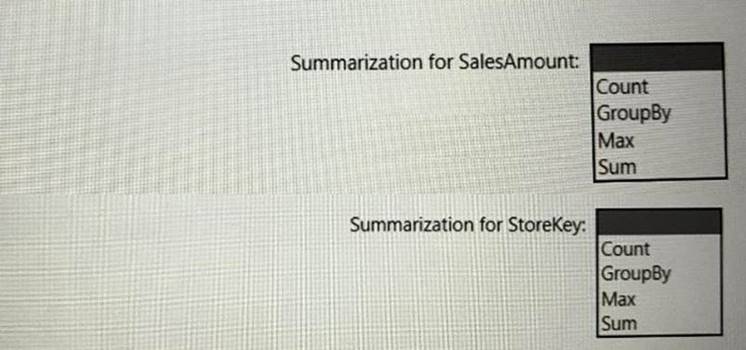
Solution:
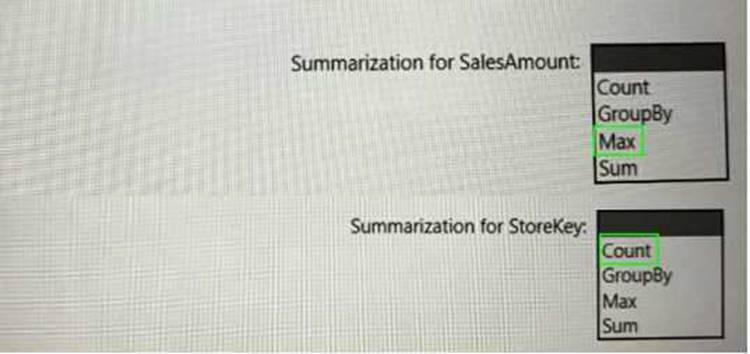
Does this meet the goal?
- A. Yes
- B. Not Mastered
Answer: A
NEW QUESTION 9
You have a kiosk that displays a Power Bl report page. The report uses a dataset that uses Import storage
mode. You need to ensure that the report page updates all the visuals every 30 minutes. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Enable Power Bl embedded.
- B. Configure the data sources to use DirectQuery.
- C. Configure the data sources to use a streaming dataset
- D. Select Auto page refresh.
- E. Enable the XMIA endpoint.
- F. Add a Microsoft Power Automate visual to the report page.
Answer: AD
NEW QUESTION 10
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.
You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend using openrowset with to explicitly define the collation for businessName and surveyName as Latim_Generai_100_BiN2_UTF8.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 11
You are creating an external table by using an Apache Spark pool in Azure Synapse Analytics. The table will contain more than 20 million rows partitioned by date. The table will be shared with the SQL engines.
You need to minimize how long it takes for a serverless SQL pool to execute a query data against the table. In which file format should you recommend storing the table data?
- A. JSON
- B. Apache Parquet
- C. CSV
- D. Delta
Answer: C
NEW QUESTION 12
You have a 2-GB Power Bl dataset.
You need to ensure that you can redeploy the dataset by using Tabular Editor. The solution must minimize how long it will take to apply changes to the dataset from powerbi.com.
Which two actions should you perform in powerbi.com? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point
- A. Enable service principal authentication for read-only admin APIs.
- B. Turn on Large dataset storage format.
- C. Connect the target workspace to an Azure Data Lake Storage Gen2 account.
- D. Enable XMLA read-write.
Answer: D
NEW QUESTION 13
You have the following code in an Azure Synapse notebook.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the code.
NOTE: Each correct selection is worth one point.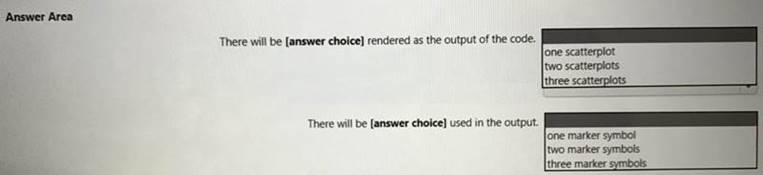
Solution:
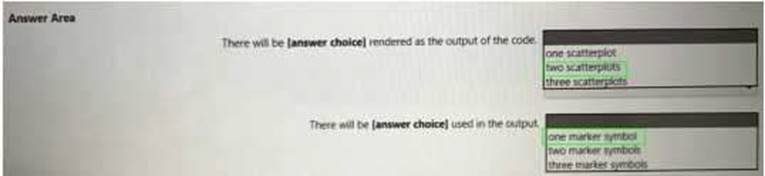
Does this meet the goal?
- A. Yes
- B. Not Mastered
Answer: A
NEW QUESTION 14
You have five Power Bl reports that contain R script data sources and R visuals.
You need to publish the reports to the Power Bl service and configure a daily refresh of datasets. What should you include in the solution?
- A. a Power Bl Embedded capacity
- B. an on-premises data gateway (standard mode)
- C. a workspace that connects to an Azure Data Lake Storage Gen2 account
- D. an on-premises data gateway (personal mode)
Answer: D
NEW QUESTION 15
You have a Power Bl workspace named Workspacel that contains five dataflows.
You need to configure Workspacel to store the dataflows in an Azure Data Lake Storage Gen2 account What should you do first?
- A. Delete the dataflow queries.
- B. From the Power Bl Admin portal, enable tenant-level storage.
- C. Disable load for all dataflow queries.
- D. Change the Data source settings in the dataflow queries.
Answer: D
NEW QUESTION 16
......
P.S. Easily pass DP-500 Exam with 83 Q&As DumpSolutions.com Dumps & pdf Version, Welcome to Download the Newest DumpSolutions.com DP-500 Dumps: https://www.dumpsolutions.com/DP-500-dumps/ (83 New Questions)