we provide Verified Microsoft 70-776 free practice exam which are the best for clearing 70-776 test, and to get certified by Microsoft Perform Big Data Engineering on Microsoft Cloud Services (beta). The 70-776 Questions & Answers covers all the knowledge points of the real 70-776 exam. Crack your Microsoft 70-776 Exam with latest dumps, guaranteed!
NEW QUESTION 1
You have an on-premises deployment of Active Directory named contoso.com. You plan to deploy a Microsoft Azure SQL data warehouse.
You need to ensure that the data warehouse can be accessed by contoso.com users.
Which two components should you deploy? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Azure AD Privileged Identity Management
- B. Azure Information Protection
- C. Azure Active Directory
- D. Azure AD Connect
- E. Cloud App Discovery
- F. Azure Active Directory B2C
Answer: CD
NEW QUESTION 2
You have a Microsoft Azure Data Lake Analytics service.
You need to write a U-SQL query to extract from a CSV file all the users who live in Boston, and then to save the results in a new CSV file.
Which U-SQL script should you use?



- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 3
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a table named Table1 that contains 3 billion rows. Table1 contains data from the last 36 months.
At the end of every month, the oldest month of data is removed based on a column named DateTime.
You need to minimize how long it takes to remove the oldest month of data. Solution: You specify DateTime as the hash distribution column.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 4
HOTSPOT
You have a Microsoft Azure Data Lake Analytics service.
You have a tab-delimited file named UserActivity.tsv that contains logs of user sessions. The file does not have a header row.
You need to create a table and to load the logs to the table. The solution must distribute the data by a column named SessionId.
How should you complete the U-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.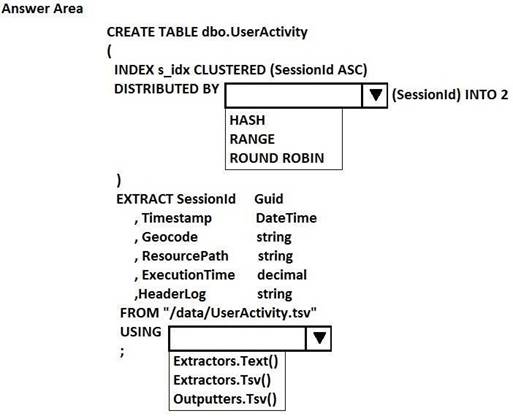
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://msdn.microsoft.com/en-us/library/mt706197.aspx
NEW QUESTION 5
You plan to add a file from Microsoft Azure Data Lake Store to Azure Data Catalog. You run the Data Catalog tool and select Data Lake Store as the data source.
Which information should you enter in the Store Account field to connect to the Data Lake Store?
- A. an email alias
- B. a server name
- C. a URL
- D. a subscription ID
Answer: C
NEW QUESTION 6
DRAG DROP
You plan to develop a solution for real-time sentiment analysis of Twitter data.
You need to create a Microsoft Azure Stream Analytics job query to count the number of tweets during a period.
Which Window function should you use for each requirement? To answer, drag the appropriate functions to the correct requirements. Each function may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
NEW QUESTION 7
You have a Microsoft Azure Data Lake Analytics service and an Azure Data Lake Store.
You need to use Python to submit a U-SQL job. Which Python module should you install?
- A. azure-mgmt-datalake-store
- B. azure-mgmt- datalake-analytics
- C. azure-datalake-store
- D. azure-mgmt-resource
Answer: B
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-manage-use- python-sdk
NEW QUESTION 8
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a clustered columnstore index.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You change the table to use a column that is not skewed for hash distribution. Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 10
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a nonclustered columnstore index.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 11
You have a Microsoft Azure SQL data warehouse named DW1 that is used only from Monday to Friday.
You need to minimize Data Warehouse Unit (DWU) usage during the weekend. What should you do?
- A. From the Azure CLI, run the account set command.
- B. Run the ALTER DATABASE statement.
- C. Call the Create or Update Database REST API.
- D. Run the Suspend-AzureRmSqlDatabase Azure PowerShell cmdlet.
Answer: D
NEW QUESTION 12
You are using Cognitive capabilities in U-SQL to analyze images that contain different types of objects.
You need to identify which objects might be people.
Which two reference assemblies should you use? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. ExtPython
- B. ImageCommon
- C. ImageTagging
- D. ExtR
- E. FaceSdk
Answer: BC
NEW QUESTION 13
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a table named Table1 that contains 3 billion rows. Table1 contains data from the last 36 months.
At the end of every month, the oldest month of data is removed based on a column named DateTime.
You need to minimize how long it takes to remove the oldest month of data. Solution: You implement round robin for table distribution.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 14
You are designing a solution that will use Microsoft Azure Data Lake Store.
You need to recommend a solution to ensure that the storage service is available if a regional outage occurs. The solution must minimize costs.
What should you recommend?
- A. Create two Data Lake Store accounts and copy the data by using Azure Data Factory.
- B. Create one Data Lake Store account that uses a monthly commitment package.
- C. Create one read-access geo-redundant storage (RA-GRS) account and configure a Recovery Services vault.
- D. Create one Data Lake Store account and create an Azure Resource Manager template that redeploys the services to a different region.
Answer: D
NEW QUESTION 15
DRAG DROP
You need to create a dataset in Microsoft Azure Data Factory that meets the following requirements: How should you complete the JSON code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://github.com/aelij/azure-content/blob/master/articles/data-factory/data-factory-create-pipelines.md
NEW QUESTION 16
DRAG DROP
You are designing a Microsoft Azure analytics solution. The solution requires that data be copied from Azure Blob storage to Azure Data Lake Store.
The data will be copied on a recurring schedule. Occasionally, the data will be copied manually. You need to recommend a solution to copy the data.
Which tools should you include in the recommendation? To answer, drag the appropriate tools to the correct requirements. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
NEW QUESTION 17
You plan to capture the output from a group of 500 IoT devices that produce approximately 10 GB of
data per hour by using Microsoft Azure Stream Analytics. The data will be retained for one year.
Once the data is processed, it will be stored in Azure, and then analyzed by using an Azure HDInsight cluster.
You need to select where to store the output data from Stream Analytics. The solution must minimize costs.
What should you select?
- A. Azure Table Storage
- B. Azure SQL Database
- C. Azure Blob storage
- D. Azure SQL Data Warehouse
Answer: C
NEW QUESTION 18
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
You need to define the schema of Table1 in AzureDF. What should you create?
- A. a gateway
- B. a linked service
- C. a dataset
- D. a pipeline
Answer: C
NEW QUESTION 19
You plan to deploy a Microsoft Azure Stream Analytics job to filter multiple input streams from IoT devices that have a total data flow of 30 MB/s.
You need to calculate how many streaming units you require for the job. The solution must prevent lag.
What is the minimum number of streaming units required?
- A. 3
- B. 10
- C. 30
- D. 300
Answer: C
NEW QUESTION 20
DRAG DROP
You use Microsoft Azure Stream Analytics to analyze data from an Azure event hub in real time and send the output to a table named Table1 in an Azure SQL database. Table1 has three columns named Date, EventID, and User.
You need to prevent duplicate data from being stored in the database.
How should you complete the statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 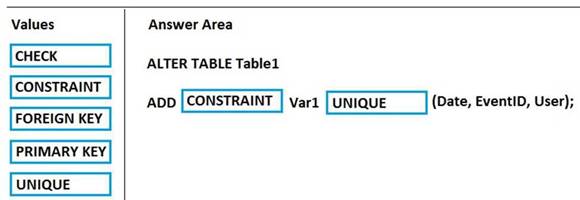
NEW QUESTION 21
You have a Microsoft Azure Data Lake Store and an Azure Active Directory tenant.
You are developing an application that will access the Data Lake Store by using end-user credentials. You need to ensure that the application uses end-user authentication to access the Data Lake Store. What should you create?
- A. a Native Active Directory app registration
- B. a policy assignment that uses the Allowed resource types policy definition
- C. a Web app/API Active Directory app registration
- D. a policy assignment that uses the Allowed locations policy definition
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-end-user-authenticate-using-active-directory
NEW QUESTION 22
......
Recommend!! Get the Full 70-776 dumps in VCE and PDF From Dumpscollection, Welcome to Download: http://www.dumpscollection.net/dumps/70-776/ (New 91 Q&As Version)