Cause all that matters here is passing the Microsoft DP-201 exam. Cause all that you need is a high score of DP-201 Designing an Azure Data Solution exam. The only one thing you need to do is downloading Ucertify DP-201 exam study guides now. We will not let you down with our money-back guarantee.
Check DP-201 free dumps before getting the full version:
NEW QUESTION 1
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
- A. Databricks Python activity
- B. Data Lake Analytics U-SQL activity
- C. HDInsight Pig activity
- D. Databricks Jar activity
Answer: C
Explanation:
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand HDInsight cluster.
References:
https://docs.microsoft.com/en-us/azure/data-factory/transform-data-using-hadoop-pig
NEW QUESTION 2
A company stores sensitive information about customers and employees in Azure SQL Database. You need to ensure that the sensitive data remains encrypted in transit and at rest.
What should you recommend?
- A. Transparent Data Encryption
- B. Always Encrypted with secure enclaves
- C. Azure Disk Encryption
- D. SQL Server AlwaysOn
Answer: B
Explanation:
References:
https://cloudblogs.microsoft.com/sqlserver/2021/12/17/confidential-computing-using-always-encrypted-withsec
NEW QUESTION 3
You need to design the Planning Assistance database.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: No
Data used for Planning Assistance must be stored in a sharded Azure SQL Database. Box 2: Yes
Box 3: Yes
Planning Assistance database will include reports tracking the travel of a single vehicle
NEW QUESTION 4
You need to design the storage for the telemetry capture system. What storage solution should you use in the design?
- A. Azure Databricks
- B. Azure SQL Data Warehouse
- C. Azure Cosmos DB
Answer: C
NEW QUESTION 5
You plan to use Azure SQL Database to support a line of business app.
You need to identify sensitive data that is stored in the database and monitor access to the data. Which three actions should you recommend? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Enable Data Discovery and Classification.
- B. Implement Transparent Data Encryption (TDE).
- C. Enable Auditing.
- D. Run Vulnerability Assessment.
- E. Use Advanced Threat Protection.
Answer: CDE
NEW QUESTION 6
You need to design the disaster recovery solution for customer sales data analytics.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Provision multiple Azure Databricks workspaces in separate Azure regions.
- B. Migrate users, notebooks, and cluster configurations from one workspace to another in the same region.
- C. Use zone redundant storage.
- D. Migrate users, notebooks, and cluster configurations from one region to another.
- E. Use Geo-redundant storage.
- F. Provision a second Azure Databricks workspace in the same region.
Answer: ADE
Explanation:
Scenario: The analytics solution for customer sales data must be available during a regional outage. To create your own regional disaster recovery topology for databricks, follow these requirements:
1. Provision multiple Azure Databricks workspaces in separate Azure regions
2. Use Geo-redundant storage.
3. Once the secondary region is created, you must migrate the users, user folders, notebooks, cluster configuration, jobs configuration, libraries, storage, init scripts, and reconfigure access control.
Note: Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9's) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 7
You are evaluating data storage solutions to support a new application.
You need to recommend a data storage solution that represents data by using nodes and relationships in graph structures.
Which data storage solution should you recommend?
- A. Blob Storage
- B. Cosmos DB
- C. Data Lake Store
- D. HDInsight
Answer: B
Explanation:
For large graphs with lots of entities and relationships, you can perform very complex analyses very quickly. Many graph databases provide a query language that you can use to traverse a network of relationships efficiently.
Relevant Azure service: Cosmos DB
References:
https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview
NEW QUESTION 8
You need to design a backup solution for the processed customer data. What should you include in the design?
- A. AzCopy
- B. AdlCopy
- C. Geo-Redundancy
- D. Geo-Replication
Answer: C
Explanation:
Scenario: All data must be backed up in case disaster recovery is required.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9's) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from
the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable. References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 9
You plan to use an Azure SQL data warehouse to store the customer data. You need to recommend a disaster recovery solution for the data warehouse. What should you include in the recommendation?
- A. AzCopy
- B. Read-only replicas
- C. AdICopy
- D. Geo-Redundant backups
Answer: D
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 10
A company stores data in multiple types of cloud-based databases.
You need to design a solution to consolidate data into a single relational database. Ingestion of data will occur at set times each day.
What should you recommend?
- A. SQL Server Migration Assistant
- B. SQL Data Sync
- C. Azure Data Factory
- D. Azure Database Migration Service
- E. Data Migration Assistant
Answer: C
Explanation:
https://docs.microsoft.com/en-us/azure/data-factory/introduction
https://azure.microsoft.com/en-us/blog/operationalize-azure-databricks-notebooks-using-data-factory/ https://azure.microsoft.com/en-us/blog/data-ingestion-into-azure-at-scale-made-easier-with-latest-enhancements
NEW QUESTION 11
You need to design the runtime environment for the Real Time Response system. What should you recommend?
- A. General Purpose nodes without the Enterprise Security package
- B. Memory Optimized Nodes without the Enterprise Security package
- C. Memory Optimized nodes with the Enterprise Security package
- D. General Purpose nodes with the Enterprise Security package
Answer: B
NEW QUESTION 12
You need to design the image processing and storage solutions.
What should you recommend? To answer, select the appropriate configuration in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale
NEW QUESTION 13
A company has locations in North America and Europe. The company uses Azure SQL Database to support business apps.
Employees must be able to access the app data in case of a region-wide outage. A multi-region availability solution is needed with the following requirements: Read-access to data in a secondary region must be available only in case of an outage of the primary region. The Azure SQL Database compute and storage layers must be integrated and replicated together.
Read-access to data in a secondary region must be available only in case of an outage of the primary region. The Azure SQL Database compute and storage layers must be integrated and replicated together.
You need to design the multi-region high availability solution.
What should you recommend? To answer, select the appropriate values in the answer area.
NOTE: Each correct selection is worth one point.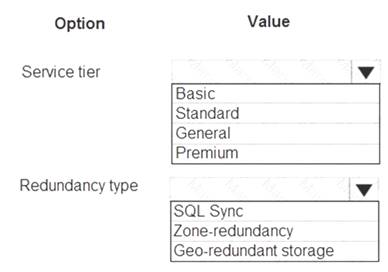
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Standard
The following table describes the types of storage accounts and their capabilities: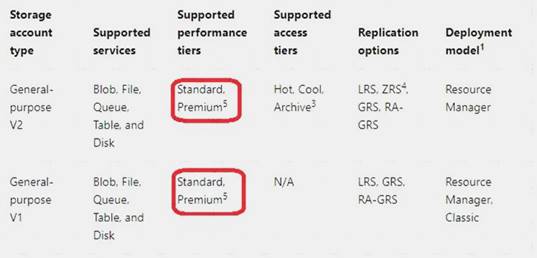
Box 2: Geo-redundant storage
If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable.
Note: If you opt for GRS, you have two related options to choose from:
GRS replicates your data to another data center in a secondary region, but that data is available to be read only if Microsoft initiates a failover from the primary to secondary region.
Read-access geo-redundant storage (RA-GRS) is based on GRS. RA-GRS replicates your data to another data center in a secondary region, and also provides you with the option to read from the secondary region. With RA-GRS, you can read from the secondary region regardless of whether Microsoft initiates a failover from the primary to secondary region.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 14
You need to ensure that performance requirements for Backtrack reports are met.
What should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.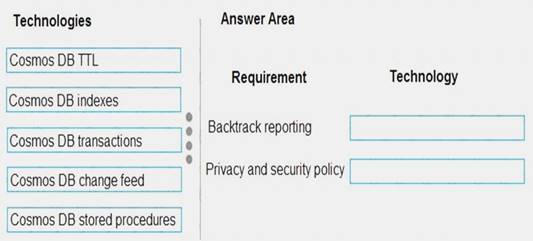
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Cosmos DB indexes
The report for Backtrack must execute as quickly as possible.
You can override the default indexing policy on an Azure Cosmos container, this could be useful if you want to tune the indexing precision to improve the query performance or to reduce the consumed storage.
Box 2: Cosmos DB TTL
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection. Users must be able to filter vehicle data in the following ways: vehicles on a specific road vehicles driving above the speed limit
vehicles on a specific road vehicles driving above the speed limit
Note: With Time to Live or TTL, Azure Cosmos DB provides the ability to delete items automatically from a container after a certain time period. By default, you can set time to live at the container level and override the value on a per-item basis. After you set the TTL at a container or at an item level, Azure Cosmos DB will automatically remove these items after the time period, since the time they were last modified.
NEW QUESTION 15
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
User-Defined Restore Points
This feature enables you to manually trigger snapshots to create restore points of your data warehouse before and after large modifications. This capability ensures that restore points are logically consistent, which provides additional data protection in case of any workload interruptions or user errors for quick recovery time.
Note: A data warehouse restore is a new data warehouse that is created from a restore point of an existing or deleted data warehouse. Restoring your data warehouse is an essential part of any business continuity and disaster recovery strategy because it re-creates your data after accidental corruption or deletion.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 16
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage. The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are smaller than 250MB. Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Ensure that files stored are larger, not smaller than 250MB.
You can have a separate compaction job that combines these files into larger ones.
Note: The file POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
Lowering the authentication checks across multiple files Reduced open file connections
Faster copying/replication
Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
NEW QUESTION 17
You have a Windows-based solution that analyzes scientific data. You are designing a cloud-based solution that performs real-time analysis of the data.
You need to design the logical flow for the solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Send data from the application to an Azure Stream Analytics job.
- B. Use an Azure Stream Analytics job on an edge devic
- C. Ingress data from an Azure Data Factory instance and build queries that output to Power BI.
- D. Use an Azure Stream Analytics job in the clou
- E. Ingress data from the Azure Event Hub instance and build queries that output to Power BI.
- F. Use an Azure Stream Analytics job in the clou
- G. Ingress data from an Azure Event Hub instance and build queries that output to Azure Data Lake Storage.
- H. Send data from the application to Azure Data Lake Storage.
- I. Send data from the application to an Azure Event Hub instance.
Answer: CF
Explanation:
Stream Analytics has first-class integration with Azure data streams as inputs from three kinds of resources: Azure Event Hubs
Azure IoT Hub Azure Blob storage References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-inputs
NEW QUESTION 18
A company installs IoT devices to monitor its fleet of delivery vehicles. Data from devices is collected from Azure Event Hub.
The data must be transmitted to Power BI for real-time data visualizations. You need to recommend a solution.
What should you recommend?
- A. Azure HDInsight with Spark Streaming
- B. Apache Spark in Azure Databricks
- C. Azure Stream Analytics
- D. Azure HDInsight with Storm
Answer: C
Explanation:
Step 1: Get your IoT hub ready for data access by adding a consumer group.
Step 2: Create, configure, and run a Stream Analytics job for data transfer from your IoT hub to your Power BI account.
Step 3: Create and publish a Power BI report to visualize the data. References:
https://docs.microsoft.com/en-us/azure/iot-hub/iot-hub-live-data-visualization-in-power-bi
NEW QUESTION 19
You are designing an Azure Databricks interactive cluster.
You need to ensure that the cluster meets the following requirements: Enable auto-termination
Retain cluster configuration indefinitely after cluster termination. What should you recommend?
- A. Start the cluster after it is terminated.
- B. Pin the cluster
- C. Clone the cluster after it is terminated.
- D. Terminate the cluster manually at process completion.
Answer: B
Explanation:
To keep an interactive cluster configuration even after it has been terminated for more than 30 days, an administrator can pin a cluster to the cluster list.
References:
https://docs.azuredatabricks.net/user-guide/clusters/terminate.html
NEW QUESTION 20
You need to design a sharding strategy for the Planning Assistance database. What should you recommend?
- A. a list mapping shard map on the binary representation of the License Plate column
- B. a range mapping shard map on the binary representation of the speed column
- C. a list mapping shard map on the location column
- D. a range mapping shard map on the time column
Answer: A
Explanation:
Data used for Planning Assistance must be stored in a sharded Azure SQL Database.
A shard typically contains items that fall within a specified range determined by one or more attributes of the data. These attributes form the shard key (sometimes referred to as the partition key). The shard key should be static. It shouldn't be based on data that might change.
References:
https://docs.microsoft.com/en-us/azure/architecture/patterns/sharding
NEW QUESTION 21
You are designing an Azure Databricks cluster that runs user-defined local processes. You need to recommend a cluster configuration that meets the following requirements:
• Minimize query latency.
• Reduce overall costs.
• Maximize the number of users that can run queries on the cluster at the same time. Which cluster type should you recommend?
- A. Standard with Autoscaling
- B. High Concurrency with Auto Termination
- C. High Concurrency with Autoscaling
- D. Standard with Auto Termination
Answer: C
Explanation:
High Concurrency clusters allow multiple users to run queries on the cluster at the same time, while minimizing query latency. Autoscaling clusters can reduce overall costs compared to a statically-sized cluster.
References:
https://docs.azuredatabricks.net/user-guide/clusters/create.html https://docs.azuredatabricks.net/user-guide/clusters/high-concurrency.html#high-concurrency https://docs.azuredatabricks.net/user-guide/clusters/terminate.html https://docs.azuredatabricks.net/user-guide/clusters/sizing.html#enable-and-configure-autoscaling
NEW QUESTION 22
......
P.S. Dumps-files.com now are offering 100% pass ensure DP-201 dumps! All DP-201 exam questions have been updated with correct answers: https://www.dumps-files.com/files/DP-201/ (74 New Questions)